Enjeux juridiques des communs de la connaissances pour les humanités numériques (2026)
 Notes de ma présentation à l’École d’été « HNU6000 Humanités numériques : fondements disciplinaires Été 2026″ du CERIUM, en association avec le Centre de Recherche Interuniversitaire sur les Humanités Numériques (CRIHN), Université de Montréal, jeudi 28 mai 2026.
Notes de ma présentation à l’École d’été « HNU6000 Humanités numériques : fondements disciplinaires Été 2026″ du CERIUM, en association avec le Centre de Recherche Interuniversitaire sur les Humanités Numériques (CRIHN), Université de Montréal, jeudi 28 mai 2026.
Cette présentation mobilise en large partie les présentations antérieures à l’École d’été ainsi qu’une présentation récente au Colloque des communs à l’UQAM avec Marjolaine Poirier, que je remercie. Voir aussi mes motes pour le mini colloque de l’ALAI à l’automne 2024. Lecture proposée: H. Le Crosnier, « Une introduction aux communs de la connaissance »
Sujet amené: À qui appartient le droit d’auteur sur ce résumé du livre de Marcello?
Sujet posé: le numérique induit des conceptions nouvelles pour les objets et les sujets des systèmes de la connaissance mais aussi de la culture, des médias et de l’information… la théorie des communs englobe les éléments conceptuels pertinents pour structurer une analyse juridique, notamment le concept de gouvernance.
Sujet divisé:
Notes méthodologiques
- L’oeuvre
- Autour de l’oeuvre
- Les données
- Les corpus
Conclusion: Chantiers juridiques pour les humanités juridiques
Notes introductives et méthodologiques
La gouvernance et le pluralisme juridique
Attention, nous crions haro sur le naturalisme et le positivisme juridique! Connaissez-vous le pluralisme juridique, la cybernétique ou la gouvernance?
L’artiste, les secteurs artistiques et l’acte de création original et la dimension naturelle du droit d’auteur. L’oeuvre comme « prolongement » naturel de l’acte de création. Le roman comme expression originale.
Les industries « trois C » (culture, communication, créatives) et la dimension positive du droit d’auteur. Mobiliser le droit de propriété quasi monopolistique pour façonner des marchés, l’importance des licences et de la gestion collective. Le marché du livre.
Les communautés utilisatrices d’oeuvres et la dimension pluraliste de l’oeuvre. Dimensions socio-économiques des contextes d’utilisation. La lecture publique.
Quid des enjeux juridiques des communs
communs numériques = objets + sujets + règles Source: Le Crosnier (et beaucoup d’autres!)
- Objets
- L’oeuvre, l’objet unitaire du droit d’auteur, un roman, un article, une peinture, une sculpture, une partition musicale…
- La métadonnée, qui représente l’oeuvre, dont certains éléments sont purement factuels (dépouillement bibliographique, par exemple) tandis que d’autres le sont (le sommaire)
- Le corpus (collection, fonds, inventaire, volume d’une revue…)
- Sujets
- renseignements personnels > droit d’auteur
- Vecteurs: application des Règles dans les interactions
- lecture/accès, écriture/enrichissement, lien, échange
Représentation dans un schéma fonctionnel:
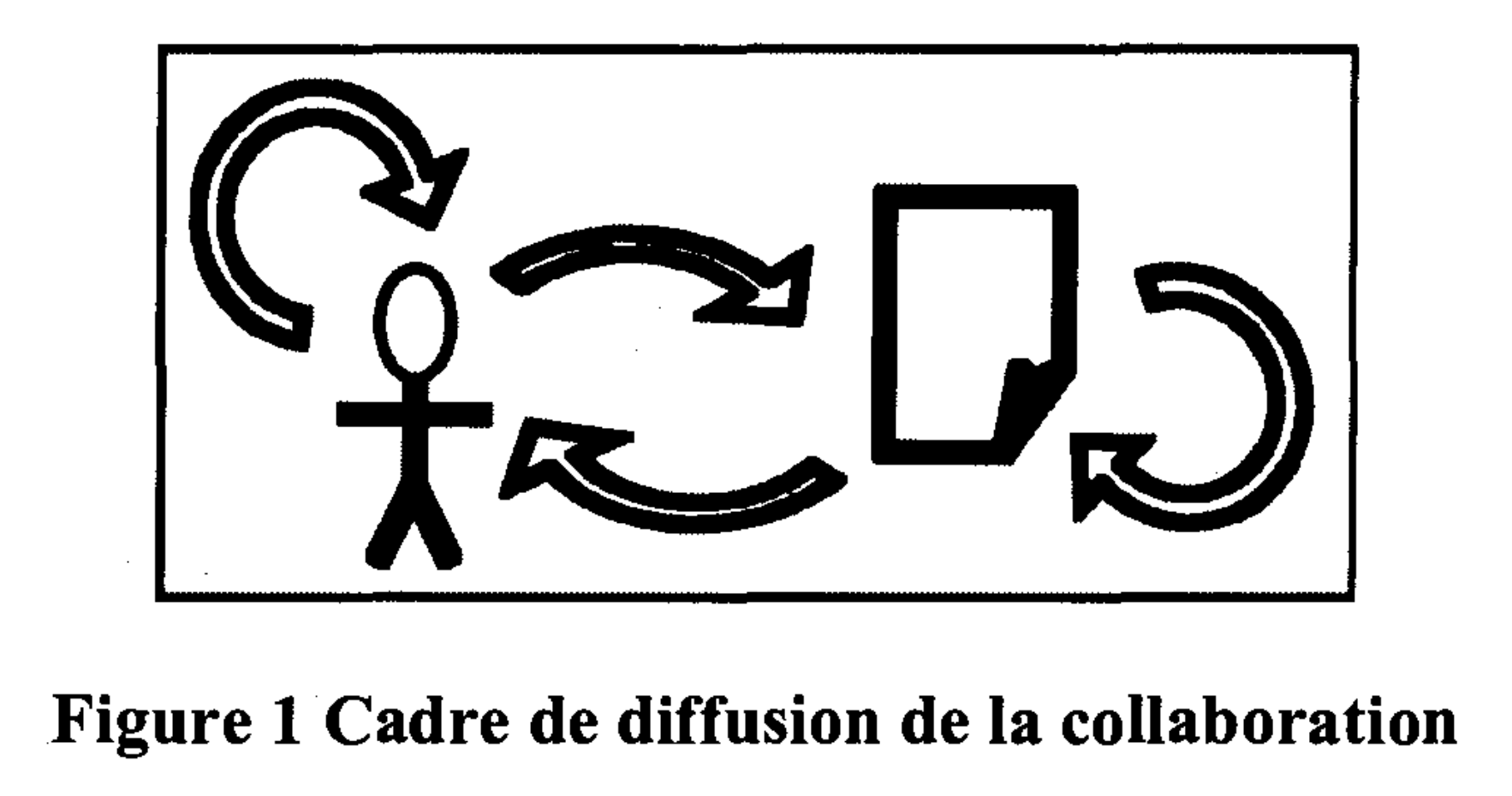
Source: La jurisprudence en accès libre à l’ère du contenu généré par les usagers [Mémoire de maîtrise en droit], Université de Montréal, 2008, p. 21
Pour résumer:
communs numériques = objets + sujets + règles
…
règle(communs) = droit d’auteur + renseignements personnels
1. L’oeuvre: droit économique et artistique
Débuts britanniques du copyright au 18e siècle: Statute of Ann (livre, 1710) et l’Acte d’Hogarth (gravure, 1734). Au 19e siècle: le droit d’auteur Français et la piraterie américaine. Convention de Berne (traité de 1886). La codification internationale des nouvelles formes médiales depuis… Internet n’est qu’un écho d’une histoire bien connue du droit d’auteur !
Loi sur le droit d’auteur, LRC 1985, c C-42, <https://canlii.ca/t/6ffg6> consulté le 2025-06-10
Propriété
art 3, https://canlii.ca/t/ckj9#art3: protection de l’oeuvre. Produire, reproduire, publier, exécuter en public l’entièreté ou une partie substantielle de la forme exprimée. En 2012, le législateur édicte la «mise à disposition par Internet» comme une méthode d’exécution en public.
Durée
art. 6, https://canlii.ca/t/ckj9#art6: durée du droit d’auteur. 70 ans après la mort de la créatrice. Après, l’utilisation n’est plus restreinte par le droit d’auteur et l’oeuvre est dans le domaine public.
Contrats, licences, cessions et toutes les concessions
art 13, https://canlii.ca/t/ckj9#art13: possession, cessions et licences. Certaines dispositions sont édictées comme point de départ, mais le droit d’auteur est agnostique quant à la teneur des contrats.
- Cession (transfert/vente) ou licence (location)
- Règle ou stratégie? Cession, mondiale, perpétuelle, exclusive, à titre gratuite
- Exception culturelle: pression morale et politique pour une configuration particulière des modalités de contrat. Rôle du code civil dans pour sa mise en oeuvre au Québec
Droit moral et artistique
art 14.1(2) https://canlii.ca/t/ckj9#art14.1: Les droits moraux sont incessibles; ils sont toutefois susceptibles de renonciation, en tout ou en partie. Encore les contrats!
2. Autour de l’oeuvre
Formes insaisissables
(fixation de l’oeuvre)Certaines formes d’expression artistiques glissent hors de la structure édictée par le droit d’auteur. La danse peut difficilement être fixée (filmer une chorégraphie protège la vidéo produite, pas la danse elle-même). Pour les artistes-interprètes musicaux, une forme de «droit voisin» est édicté. La mode est généralement exclue du droit d’auteur au Canada.
Les savoirs traditionnels et les formes d’expressions autochtones sont des formes qui glissent également (fort malheureusement) de la structure du droit d’auteur, tout comme le patrimoine vivant.
Limitations
Les limitations édictent une utilisation sans autorisation mais rémunérée. Les Société de gestion collectives (SGC) sont les organisations appelées à gérer les droits sur un corpus homogène d’oeuvres pour une communauté donnée. Copibec gère la réprographie au Québec. Dans l’industrie, on parle des «petits droits» pour ceux gérées par les SGC.
Exceptions
Les exceptions édictent une utilisation sans autorisation et sans rémunération. L’utilisation équitable aux art. 29, 29.1 et 29.2. Le contenu non-commercial généré par les utilisateurs à l’art 29.21. Les Bibliothèques, archives et musées (BAM) aux art. 30.1 et 30.2.
Synthèse
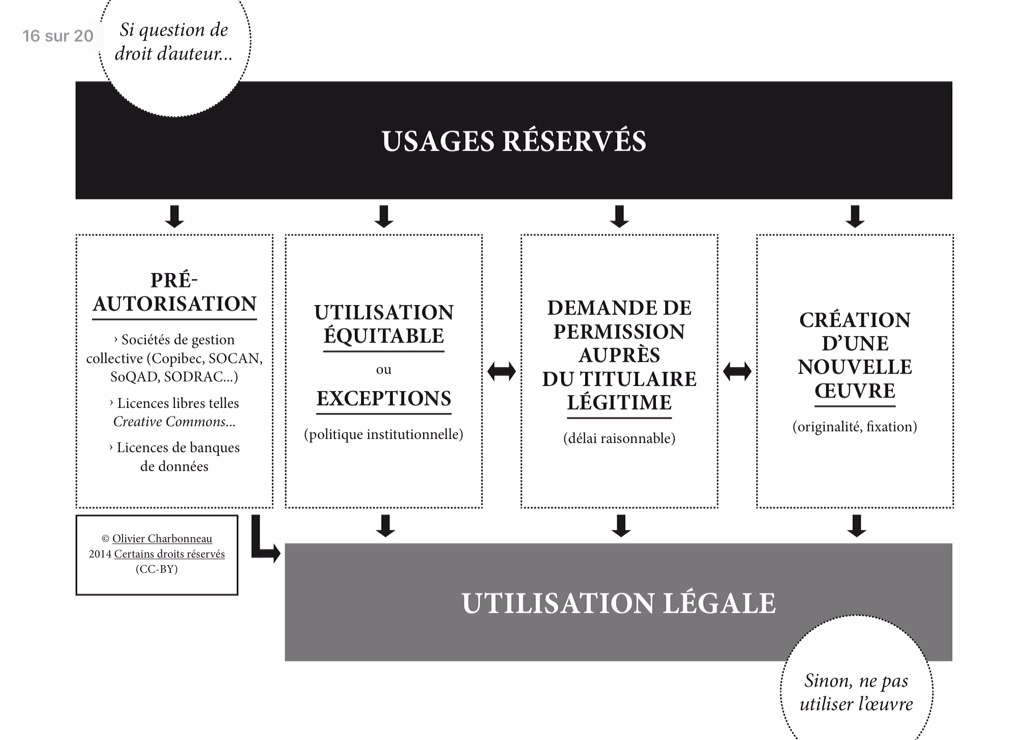
3. Les données: La question de l’originalité (juridique!)
Le droit d’auteur protège les oeuvres originales et fixées. Les faits ne sont pas originales à moins que la sélection et l’arrangement de ceux-ci découle du talent, jugement et de l’effort. Une recette n’est pas protégée, à moins de se qualifier comme originale dans la forme qu’elle est exprimée. Les idées ne sont pas protégées par droit d’auteur.
Est-ce que les données sont protégées par droit d’auteur?
Essentiellement, la compilation, pour être originale, doit être une œuvre que son auteur a créée de façon indépendante et qui, par les choix dont elle résulte et par son arrangement, dénote un degré minimal de talent, de jugement et de travail. Ce n’est pas une haute exigence, mais c’en est une. S’il en était autrement, n’importe quel type de choix ou d’arrangement suffirait, puisque ces opérations supposent un certain effort intellectuel. Toutefois, la Loi est claire: seules les œuvres originales sont protégées. Il se peut donc que certaines compilations ne satisfassent pas à ce critère. Source: Télé-Direct (Publications) Inc. c. American Business Information, Inc., [1998] 2 CF 22, 1997 CanLII 6378 (CAF), <http://canlii.ca/t/4mzd>
Est-ce que la numérisation d’une oeuvre du domaine public introduit un « nouveau » droit d’auteur?
- Premier cas: la numérisation homéostatique d’un manuscrit médiéval ou d’un livre imprimé du 19e siècle
- Ensuite, ledit manuscrit maintenant encodé avec avec le schéma
- Second cas: une pellicule de film
- Troisième cas: une sculpture
4. Corpus = données + oeuvres
La sélection et l’arrangement des données et des oeuvres découlent de la discipline et de la méthode appliquée. Il est possible de changer la nature des oeuvres et des données en les traitant, en les enrichissant:
Données ouvertes et liées
Encodage standardisé (cf. TEI avec Joanna ce PM)
Libre accès
…
La valeur symbolique, structurante et stratégique des corpus : ils sont essentiels pour les intelligences artificielles!
IA = corpus + fonctions + paramêtres (poids) + output
D’ailleurs, avec le numérique, il est possible d’offrir plusieurs licences différentes pour les mêmes objets de droit à différents sujets. Il est préférable de valider les perspectives juridiques par une entente écrite.
- Métadonnée juridique
- Politique institutionnelle (ou la méthode en humanités numériqies)
Le chantier juridique pour un projet en humanités juridiques
Le chantier juridique constitue une étape de validation pour articuler les approches souhaitées aux situations complexes en droit. Il s’agit d’un exercice qui peut s’étaler sur plusieurs années autour des oeuvres, métadonnées et corpus visés, en lien avec les communautés actives dans un projet.
Matrice oeuvre / utilisation pour décortiquer les métadonnées juridiques pour des classes homogènes d’oeuvres protégées en vue de contextes d’utilisations. Regarder en amont et en aval, le cycle de vie des oeuvres sous votre égide. Veille sur les formats technologiques, l’offre et les pratiques du marché (eg. nombre d’exemplaires), les licences…
Politique institutionnelle pour codifier les 4 utilisations légitimes identifiées dans la figure ci-dessus. Le vrai défi est d’identifier les personnes responsables de documenter les processus et de prendre des décisions sur les risques. La politique doit être assortie de l’entité responsable d’émettre, mobiliser et faire respecter des lignes directrices (procédures) sur les dimensions d’utilisation légitime. Les lignes directrices (procédures) sont en phase avec les métadonnées juridiques.
Les phases pertinentes sont:
- Un inventaire des « classes documentaires (œuvres) » (collections / corpus / etc.) en fonction de leur statut juridique;
- Un inventaire des « contextes d’utilisation » (services documentaires) des collections ou, en HN, les disciplines et les méthodes;
- Une synthèse des considérations juridiques des conditions d’acquisition des documents; puis
- La production d’une matrice œuvres-utilisation;
- L’élaboration d’une politique et de quelques procédures sur le droit d’auteur, qui doivent «cheminer» aux bonnes instances par le truchement des métadonnées juridiques.
Exemple: le projet des Savoirs communs du cinéma de la Cinémathèque Québécoise.
Donc, en humanités juridiques, il est nécessaire de définir les métadonnées juridiques de chaque instance documentaire (oeuvre) ainsi que les politiques institutionnelles pour les sujets désirant mobiliser les corpus.
