Archives
Ces pages furent créées dans le passé et je ne veux ni les diffuser, ni les effacer.
Conférence CultureLibre.ca
Enjeux juridiques des communs de la connaissances pour les humanités numériques (2026)
Olivier Charbonneau 2026-05-28
 Notes de ma présentation à l’École d’été « HNU6000 Humanités numériques : fondements disciplinaires Été 2026″ du CERIUM, en association avec le Centre de Recherche Interuniversitaire sur les Humanités Numériques (CRIHN), Université de Montréal, jeudi 28 mai 2026.
Notes de ma présentation à l’École d’été « HNU6000 Humanités numériques : fondements disciplinaires Été 2026″ du CERIUM, en association avec le Centre de Recherche Interuniversitaire sur les Humanités Numériques (CRIHN), Université de Montréal, jeudi 28 mai 2026.
Cette présentation mobilise en large partie les présentations antérieures à l’École d’été ainsi qu’une présentation récente au Colloque des communs à l’UQAM avec Marjolaine Poirier, que je remercie. Voir aussi mes motes pour le mini colloque de l’ALAI à l’automne 2024. Lecture proposée: H. Le Crosnier, « Une introduction aux communs de la connaissance »
Sujet amené: À qui appartient le droit d’auteur sur ce résumé du livre de Marcello?
Sujet posé: le numérique induit des conceptions nouvelles pour les objets et les sujets des systèmes de la connaissance mais aussi de la culture, des médias et de l’information… la théorie des communs englobe les éléments conceptuels pertinents pour structurer une analyse juridique, notamment le concept de gouvernance.
Sujet divisé:
Notes méthodologiques
- L’oeuvre
- Autour de l’oeuvre
- Les données
- Les corpus
Conclusion: Chantiers juridiques pour les humanités juridiques
Notes introductives et méthodologiques
La gouvernance et le pluralisme juridique
Attention, nous crions haro sur le naturalisme et le positivisme juridique! Connaissez-vous le pluralisme juridique, la cybernétique ou la gouvernance?
L’artiste, les secteurs artistiques et l’acte de création original et la dimension naturelle du droit d’auteur. L’oeuvre comme « prolongement » naturel de l’acte de création. Le roman comme expression originale.
Les industries « trois C » (culture, communication, créatives) et la dimension positive du droit d’auteur. Mobiliser le droit de propriété quasi monopolistique pour façonner des marchés, l’importance des licences et de la gestion collective. Le marché du livre.
Les communautés utilisatrices d’oeuvres et la dimension pluraliste de l’oeuvre. Dimensions socio-économiques des contextes d’utilisation. La lecture publique.
Quid des enjeux juridiques des communs
communs numériques = objets + sujets + règles Source: Le Crosnier (et beaucoup d’autres!)
- Objets
- L’oeuvre, l’objet unitaire du droit d’auteur, un roman, un article, une peinture, une sculpture, une partition musicale…
- La métadonnée, qui représente l’oeuvre, dont certains éléments sont purement factuels (dépouillement bibliographique, par exemple) tandis que d’autres le sont (le sommaire)
- Le corpus (collection, fonds, inventaire, volume d’une revue…)
- Sujets
- renseignements personnels > droit d’auteur
- Vecteurs: application des Règles dans les interactions
- lecture/accès, écriture/enrichissement, lien, échange
Représentation dans un schéma fonctionnel:
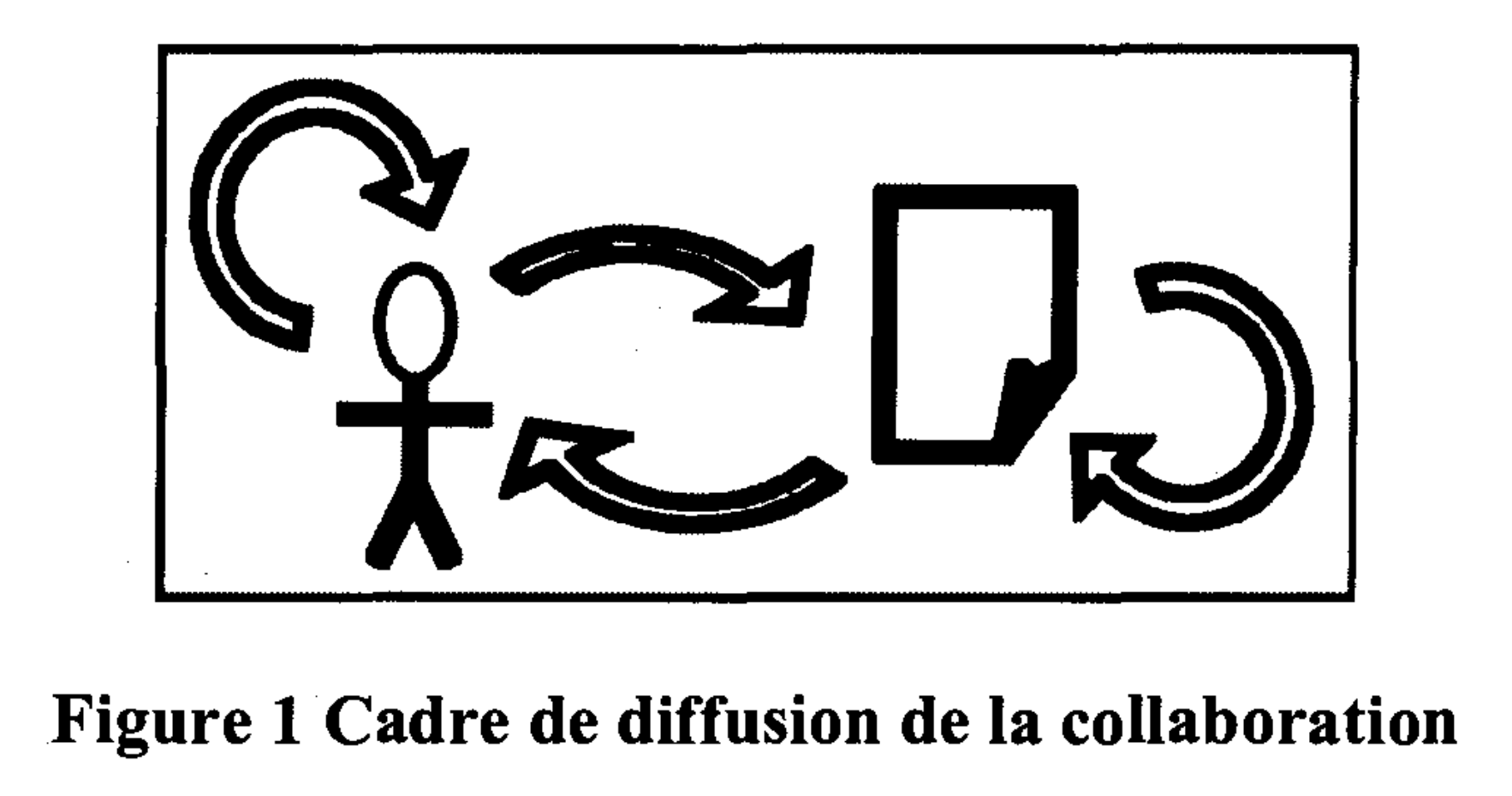
Source: La jurisprudence en accès libre à l’ère du contenu généré par les usagers [Mémoire de maîtrise en droit], Université de Montréal, 2008, p. 21
Pour résumer:
communs numériques = objets + sujets + règles
…
règle(communs) = droit d’auteur + renseignements personnels
1. L’oeuvre: droit économique et artistique
Débuts britanniques du copyright au 18e siècle: Statute of Ann (livre, 1710) et l’Acte d’Hogarth (gravure, 1734). Au 19e siècle: le droit d’auteur Français et la piraterie américaine. Convention de Berne (traité de 1886). La codification internationale des nouvelles formes médiales depuis… Internet n’est qu’un écho d’une histoire bien connue du droit d’auteur !
Loi sur le droit d’auteur, LRC 1985, c C-42, <https://canlii.ca/t/6ffg6> consulté le 2025-06-10
Propriété
art 3, https://canlii.ca/t/ckj9#art3: protection de l’oeuvre. Produire, reproduire, publier, exécuter en public l’entièreté ou une partie substantielle de la forme exprimée. En 2012, le législateur édicte la «mise à disposition par Internet» comme une méthode d’exécution en public.
Durée
art. 6, https://canlii.ca/t/ckj9#art6: durée du droit d’auteur. 70 ans après la mort de la créatrice. Après, l’utilisation n’est plus restreinte par le droit d’auteur et l’oeuvre est dans le domaine public.
Contrats, licences, cessions et toutes les concessions
art 13, https://canlii.ca/t/ckj9#art13: possession, cessions et licences. Certaines dispositions sont édictées comme point de départ, mais le droit d’auteur est agnostique quant à la teneur des contrats.
- Cession (transfert/vente) ou licence (location)
- Règle ou stratégie? Cession, mondiale, perpétuelle, exclusive, à titre gratuite
- Exception culturelle: pression morale et politique pour une configuration particulière des modalités de contrat. Rôle du code civil dans pour sa mise en oeuvre au Québec
Droit moral et artistique
art 14.1(2) https://canlii.ca/t/ckj9#art14.1: Les droits moraux sont incessibles; ils sont toutefois susceptibles de renonciation, en tout ou en partie. Encore les contrats!
2. Autour de l’oeuvre
Formes insaisissables
(fixation de l’oeuvre)Certaines formes d’expression artistiques glissent hors de la structure édictée par le droit d’auteur. La danse peut difficilement être fixée (filmer une chorégraphie protège la vidéo produite, pas la danse elle-même). Pour les artistes-interprètes musicaux, une forme de «droit voisin» est édicté. La mode est généralement exclue du droit d’auteur au Canada.
Les savoirs traditionnels et les formes d’expressions autochtones sont des formes qui glissent également (fort malheureusement) de la structure du droit d’auteur, tout comme le patrimoine vivant.
Limitations
Les limitations édictent une utilisation sans autorisation mais rémunérée. Les Société de gestion collectives (SGC) sont les organisations appelées à gérer les droits sur un corpus homogène d’oeuvres pour une communauté donnée. Copibec gère la réprographie au Québec. Dans l’industrie, on parle des «petits droits» pour ceux gérées par les SGC.
Exceptions
Les exceptions édictent une utilisation sans autorisation et sans rémunération. L’utilisation équitable aux art. 29, 29.1 et 29.2. Le contenu non-commercial généré par les utilisateurs à l’art 29.21. Les Bibliothèques, archives et musées (BAM) aux art. 30.1 et 30.2.
Synthèse

3. Les données: La question de l’originalité (juridique!)
Le droit d’auteur protège les oeuvres originales et fixées. Les faits ne sont pas originales à moins que la sélection et l’arrangement de ceux-ci découle du talent, jugement et de l’effort. Une recette n’est pas protégée, à moins de se qualifier comme originale dans la forme qu’elle est exprimée. Les idées ne sont pas protégées par droit d’auteur.
Est-ce que les données sont protégées par droit d’auteur?
Essentiellement, la compilation, pour être originale, doit être une œuvre que son auteur a créée de façon indépendante et qui, par les choix dont elle résulte et par son arrangement, dénote un degré minimal de talent, de jugement et de travail. Ce n’est pas une haute exigence, mais c’en est une. S’il en était autrement, n’importe quel type de choix ou d’arrangement suffirait, puisque ces opérations supposent un certain effort intellectuel. Toutefois, la Loi est claire: seules les œuvres originales sont protégées. Il se peut donc que certaines compilations ne satisfassent pas à ce critère. Source: Télé-Direct (Publications) Inc. c. American Business Information, Inc., [1998] 2 CF 22, 1997 CanLII 6378 (CAF), <http://canlii.ca/t/4mzd>
Est-ce que la numérisation d’une oeuvre du domaine public introduit un « nouveau » droit d’auteur?
- Premier cas: la numérisation homéostatique d’un manuscrit médiéval ou d’un livre imprimé du 19e siècle
- Ensuite, ledit manuscrit maintenant encodé avec avec le schéma
- Second cas: une pellicule de film
- Troisième cas: une sculpture
4. Corpus = données + oeuvres
La sélection et l’arrangement des données et des oeuvres découlent de la discipline et de la méthode appliquée. Il est possible de changer la nature des oeuvres et des données en les traitant, en les enrichissant:
Données ouvertes et liées
Encodage standardisé (cf. TEI avec Joanna ce PM)
Libre accès
…
La valeur symbolique, structurante et stratégique des corpus : ils sont essentiels pour les intelligences artificielles!
IA = corpus + fonctions + paramêtres (poids) + output
D’ailleurs, avec le numérique, il est possible d’offrir plusieurs licences différentes pour les mêmes objets de droit à différents sujets. Il est préférable de valider les perspectives juridiques par une entente écrite.
- Métadonnée juridique
- Politique institutionnelle (ou la méthode en humanités numériqies)
Le chantier juridique pour un projet en humanités juridiques
Le chantier juridique constitue une étape de validation pour articuler les approches souhaitées aux situations complexes en droit. Il s’agit d’un exercice qui peut s’étaler sur plusieurs années autour des oeuvres, métadonnées et corpus visés, en lien avec les communautés actives dans un projet.
Matrice oeuvre / utilisation pour décortiquer les métadonnées juridiques pour des classes homogènes d’oeuvres protégées en vue de contextes d’utilisations. Regarder en amont et en aval, le cycle de vie des oeuvres sous votre égide. Veille sur les formats technologiques, l’offre et les pratiques du marché (eg. nombre d’exemplaires), les licences…
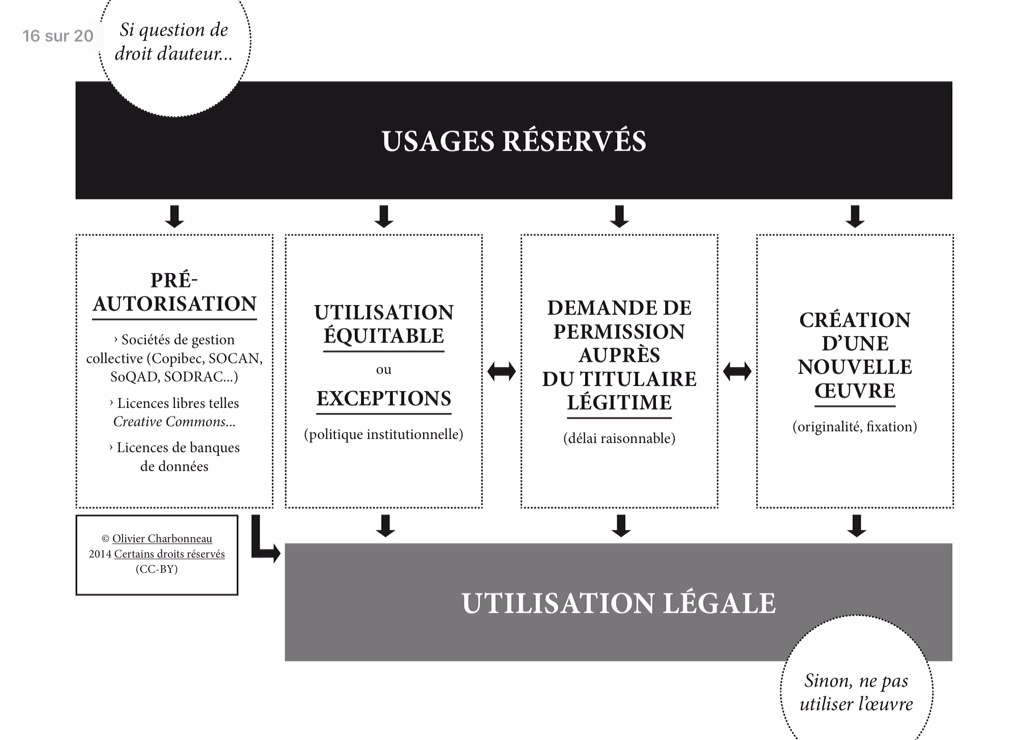
Politique institutionnelle pour codifier les 4 utilisations légitimes identifiées dans la figure ci-dessus. Le vrai défi est d’identifier les personnes responsables de documenter les processus et de prendre des décisions sur les risques. La politique doit être assortie de l’entité responsable d’émettre, mobiliser et faire respecter des lignes directrices (procédures) sur les dimensions d’utilisation légitime. Les lignes directrices (procédures) sont en phase avec les métadonnées juridiques.
Les phases pertinentes sont:
- Un inventaire des « classes documentaires (œuvres) » (collections / corpus / etc.) en fonction de leur statut juridique;
- Un inventaire des « contextes d’utilisation » (services documentaires) des collections ou, en HN, les disciplines et les méthodes;
- Une synthèse des considérations juridiques des conditions d’acquisition des documents; puis
- La production d’une matrice œuvres-utilisation;
- L’élaboration d’une politique et de quelques procédures sur le droit d’auteur, qui doivent «cheminer» aux bonnes instances par le truchement des métadonnées juridiques.
Exemple: le projet des Savoirs communs du cinéma de la Cinémathèque Québécoise.
Donc, en humanités juridiques, il est nécessaire de définir les métadonnées juridiques de chaque instance documentaire (oeuvre) ainsi que les politiques institutionnelles pour les sujets désirant mobiliser les corpus.
CultureLibre.ca
Lignes directrices du TP5 sur l’intelligence artificielle générative
Olivier Charbonneau 2026-04-07
Les efforts au niveau universitaire requiert un effort de réflexion, de créativité, de pensée critique, et de jugement dans la sélection et l’arrangements des éléments présentés lors des évaluations et travaux. Il est également essentiel d’avoir recours à des sources fiables, académiques et pertinentes dans l’élaboration de ceux-ci.
Par ailleurs, les outils de l’intelligence artificielle générative permettent d’accélérer certains processus d’apprentissage, tels que la synthèse de documents complexe, des explorations autours de concepts difficiles ou une analyse stylistique et orthographique de nos propres textes. Par contre, certainnes utilisation de l’IAGen sont néfastes à l’apprentissage et sont considérées comme une infraction à la probité académique, notamment le copier-coller sans attribution de passages dans vos travaux. Tout est une question d’équilibre.
Afin de susciter la réflexion et le dialogue sur ces points, vous devez produire un texte de 250 à 400 mots sur votre utilisation des outils de l’intelligence artificielle générative dans le contexte de ce cours. Ce texte doit être déposé dans le dépôt du site Moodle de notre cours avant le 22 avril à 23h59.
Spécifiquement, vous devez préciser quel(s) outil(s) GenAI ont été utilisés (ChatGPT, Gemeni, Claude…), comment ils ont été utilisés et comment les résultats générés par le ou les outils ont été intégrés aux travaux soumis. Une dernière section concerne une déclaration personnelle sur votre appréciation de ces outils.
CultureLibre.ca
Modalités pour le travail final et l’exposé oral
Olivier Charbonneau 2026-03-28
Le cours COM5003 tire à sa fin, discutons des modalités finales, notamment le travail final et l’exposé oral.
Le travail final du cours COM5003 consiste à explorer les thèmes reliés au cours dans un travail universitaire classique ou une production créative. L’exposé oral, quant à lui, offre l’opportunité de partager nos découvertes avec le reste des personnes du cours. Voici quelques modalités supplémentaires pour chacune de ces activités d’apprentissage.
Travail final
Le but du travail final consiste à démontrer votre compréhension d’enjeu(x) socio-économiques de la création wed et la propriété intellectuelle. Ce travail doit représenter une synthèse des apprentissages du cours et représente un effort considérable de votre part.
Chaque personne doit produire un travail d’une dizaine de pages, avec au moins 6 références académiques, sur les thèmes du cours. Le travail peut se faire en groupe, le cas échéant, les modalités sont multipliées par le nombre de personnes. Par exemple, pour deux personnes, le travail final est d’une vingtaine de page avec au moin une douzaine de références au total. Un travail créatif est autorisé, le cas échéant il est nécessaire pour les personnes étudiantes de proposer un format qui respecte les modalités en terme de travail.
Modalités particulières
Donc, vous avez deux options:
- La production d’un travail de 10 pages (excluant la bibliographie ou les annexes) pour approfondir un des thèmes présentés dans le cadre du cours. Il s’agit d’une synthèse d’un sujet complexe que vous approfondissez grâce à des sources, au moins 6, pertinentes et ayant une autorité, tels des rapports gouvernementaux, des articles scientifiques ou des livres de la bibliothèque Universitaire.
- La production d’un projet de création web. Dans ce cas, il est nécessaire de mettre l’emphase sur les enjeux socio-économiques de la création web et la propriété intellectuelle de votre projet, il ne s’agit pas uniquement d’un « plan de comm » ou d’un épisode de balado. Par exemple, un projet personnel du développement d’un site Internet doit exposer et explorer les clientèles, les outils technologiques et les questions juridiques de votre projet: d’où provient les images, la musique, les vidéo? Qui possèdent les droits? Que doivent prévoir les contrats, licences et conditions d’utilisation? Vous devez produire un plan de développement qui explore ces points ainsi que la maquette de votre projet de création web. Vous devez également consulter et citer des sources pertinentes, à l’instar de l’option 1.
En ce qui concerne les modalités particulières, voici quelques éléments:
- Si vous êtes en groupe de deux, vous pouvez présenter en duo, souvent l’adage suivant: le double à deux. Vous « additionnez » vos travaux, en termes d’efforts et de durée.
- Vous serez notés en vertu de la qualité de l’exécution (français, structure, cohérence, table des matières, etc.) ainsi que le contenu intellectuel de votre travail.
- Vous devez produire page de couverture, une table des matières, une bibliographie et ce, dans un seul document (avec les ajustements nécessaires pour un projet de création web, au besoin).
Remise
Le travail doit être remis par l’entremise d’un dépôt dans Moodle. Il sera ouvert le 7 avril restera ouvert jusqu’au 22 avril à 23h59.
Exposé oral
L’exposé oral est de 5 à 8 minutes en classe, par personne dans le groupe. L’objectif est de partager vos efforts de recherche aux autres personnes du cours.
Modalités particulières
- Dans un soucis d’équité, j’ai attribué l’ordre des présentations aléatoirement. Puisqu’il s’agit d’une évaluation, la seule façon de les déplacer consiste à justifier cette demande en vertu de la politique universitaire. Désolé si j’ai oublié de grouper les présentations de binômes: les groupes présenterons lors de la séance de la première personne listée.
- Si vous êtes en groupe de deux, vous pouvez présenter en duo, souvent l’adage suivant: le double à deux. Vous « additionnez » vos travaux, en termes d’efforts et de durée.
- Chaque présentation sera de 5 à 8 minutes, suivi d’une période pour des questions (donc 10 à 16 minutes à deux).
- Je vous demande de présenter l’état d’avancée de votre travail final.
- Tel que discuté au dernier cours, vous serez notés sur deux éléments fondamentaux: 1. la qualité de l’exécution (français oral, cohérence, etc.) pour 5 points sur 15 ainsi que 2. le contenu intellectuel de vos propos (sélection et arrangement démontrant du talent, du jugement et de l’effort) pour 10 points sur 15.
- Votre présence est requise, avec votre caméra allumée, comme toujours, même si vous ne présentez pas lors de ce cours. Une partie des points de participation du cours est prévue pour cet aspect.
- Astuce: Imaginez que nous sommes un groupe de recherche (ou une équipe dans une agence de communication). Chacun d’entre nous avons à préparer un « gros rapport final » (e.g.: le travail final) sur les enjeux socio-économiques de la PI et la création web (soit sous la forme d’un travail écrit de 10-15 pages, soit comme un projet de création :: voir détails ici-bas). La présentation orale consiste à offrir à vos pairs et collègues, une version orale de ce travail final.
Remise
L’ordre des présentations sera discuté lors de la séance du 31 mars.
CultureLibre.ca
Cosignes pour le TP4: Images, son, etc.
Olivier Charbonneau 2026-03-17
L’objectif du quatrième travail pratique consiste à réfléchir sur la source des documents (dont nous ne sommes pas les créatrices.teurs) que l’on désire inclure dans son travail final (ou toute autre initiative de création web). Je vous demande de produire un rapport concis où vous présentez votre choix de documents produits par des tiers pour accompagner votre présentation orale ou votre travail final.
Spécifiquement, vous devez repérer au moins quatre (4) documents, qu’ils soient des images (des illustrations, infographies, logos de compagnies, mèmes internet, etc.), des sons (clips musicaux, bibliothèque de sons) ou tout autre document pertinent, que vous désirez imbriquer dans votre travail final. Vous pouvez inclure un document provenant d’une Intelligence artificielle, telle ChatGPT ou DALL-e.
Pour chacun des six documents de ce TP4, vous devez décrire les éléments suivants dans texte continu, séparé par des intertitres du même niveau pour chaque document :
- Les éléments de référence bibliographique avec le lien Internet;
- Une petite description de l’importance de ce fichier pour votre projet;
- La source du fichier, c’est-à-dire où vous l’avez déniché;
- La situation juridique du fichier: Soit que le document est dans le domaine public, soit qu’il est sous licence, soit que nous avons recours à une exception au droit d’auteur pour son utilisation. Y a-t-il des questions quant aux renseignements personnels? À la liberté d’expression? Expliquez en quoi ces éléments vous contraignent ou facilite l’utilisation du document visé.
Étant donné la taille de certains fichiers d’image, audio ou vidéo, il n’est pas nécessaire d’inclure le/les fichiers numérique de chaque document visé. Il est nécessaire d’inclure les quatre éléments pour chacun des trois documents à inclure. Vous pouvez verser votre texte dans la place correspondante à ce TP4 directement dans Moodle.
Date limite: 25 mars 2026, avant 23h59
Pour vous aider, voici quelques portails pertinents pour dénicher du contenu numérique:
CultureLibre.ca
Lectures pour la séance #10 (17 mars 2026)
Olivier Charbonneau 2026-03-10
Lectures obligatoires
#web #droit Érika BERGERON-DROLET, Olivier CHARBONNEAU et Guillaume DÉZIEL, «Le droit d’auteur», dans Charlaine Bouchard (dir.), Comment la chaîne de bloc va transformer le droit, Montréal, Éditions Yvon Blais, 2020, p. 191-210, <https://canlii.ca/t/xn9s>, consulté le 2026-03-10
Lectures complémentaires
#web #droit Diop, R. (2023). La gouvernance décentralisée des chaînes de blocs : mythe ou réalité du code. Lex Electronica, 28(1), 200–227. https://doi.org/10.7202/1108627ar
CultureLibre.ca
Consignes pour le TP3: la bibliographie annotée
Olivier Charbonneau 2026-02-24
Le TP3 doit être déposé dans votre page où vous présentez votre projet dans le Wiki du cours avant le mardi 10 mars avant 23h59. Nous pourrons travailler sur votre TP3 lors de ce cours.
Nous avons discuté de plusieurs précisions lors des derniers cours, voici le sommaire de celles-ci:
- Une bibliographie annotée de 4 à 6 sources, dont au moins sources 3 académiques (article savant ou chapitre de livre) et/ou une source gouvernementales (un rapport d’au moins 6 pages avec citations, peu importe le pays). La source gouvernementale est optionnelle. Demandez de l’aide du service de référence de la bibliothèque pour savoir ce qu’est une source académique ou gouvernementale.
- Pour être clair: une source académique doit absolument avoir une bibliographie qui recense des citations provenant d’autres sources académiques. Demandez à la bibliothèque pour de l’assistance, je ne répondrai pas à vos demande d’aide sur ce point.
- Les éléments de la bibliographie annotée doivent être nouveaux, pas tirées des lectures du cours.
- Vous pouvez annoter des lectures obligatoires du cours mais celles-ci ne seront pas comptabilisées dans celles que je veux voir.
- Si vous avez beaucoup d’articles académiques, choisissez les plus pertinents.
- Vous allez avoir la liberté de citer toutes les sources que vous voulez dans le travail final, mais je veux voir les sources intellectuelles de votre travail à cette étape.
- Évitez d’annoter des pages webs, même si elles résument bien les thèmes qui vous intéressent.
Suivre les consignes de diffusées par prof. Marc André Roberge pour une bibliographie annotée:
Définition : Une bibliographie annotée consiste en une liste d’ouvrages dont chacune des entrées est suivie d’un paragraphe descriptif et critique. Elle permet de renseigner le lecteur sur l’utilité d’un ouvrage, son contenu et ses particularités de même que sur ses principales qualités et défauts.
Ampleur : Une bibliographie annotée peut porter sur un choix limité d’ouvrages ou encore sur l’ensemble de la littérature sur un sujet. Une annotation ne devrait généralement pas dépasser 150 mots; elle peut aussi être beaucoup plus brève et se limiter à quelques phrases.
Mise en page : Chaque ouvrage fait l’objet d’une notice bibliographique complète respectant les règles du protocole utilisé, avec alignement en sommaire simple (angl. hanging indentation). En d’autres mots, la première ligne est alignée avec la marge et les lignes suivantes sont renfoncées d’une tabulation. L’annotation suit, précédée ou non d’une ligne blanche; elle est généralement en retrait d’une tabulation avec une renfoncement initial facultatif.
Critères d’évaluation : On pourra s’inspirer de ce qui suit pour établir le contenu de l’annotation. Il se peut que seuls certains des éléments proposés ici soient pertinents pour un titre donné :
– brève identification de l’auteur permettant de lui donner une crédibilité;
– importance de l’ouvrage compte tenu de l’état de la recherche;
– identification des grandes hypothèses, le cas échéant;
– description des principaux sujets traités;
– identification des sections ou caractéristiques particulièrement utiles (listes, tableaux, appendices, exemples musicaux, index, etc.);
– type de public auquel est destiné l’ouvrage.
Style télégraphique : Bien qu’une annotation puisse être rédigée comme un texte descriptif traditionnel, c’est-à-dire composée de phrases avec sujet, verbe et complément, on peut utiliser un style télégraphique, particulièrement si le nombre d’annotations est très élevé.Source: Roberge, Marc-André. Guide des difficultés de rédaction en musique (GDRM). Université Laval, Faculté de musique. Consulté le 6 septembre 2002.
Il est possible de retrouver des exemples de bibliographie annotée, comme celle-ci traitant de l’histoire politique du Nicaragua (source: UQAM) ou les p. 81 à 84 de ce guide de l’université d’Ottawa.
CultureLibre.ca
Lectures pour la séance #7
Olivier Charbonneau 2026-02-17
Lectures obligatoires
#Web #Droit Principaux changements aux lois sur la protection des renseignements personnels, Commission d’accès à l’information, Gouvernement du Québec https://www.cai.gouv.qc.ca/protection-renseignements-personnels/sujets-et-domaines-dinteret/principaux-changements-loi-25
#Web #Droit Ledy Rivas Zannou, Profilage en ligne et protection des renseignements personnels – Pour en finir avec le mythe du consentement !, 2023 101-1 Revue du Barreau canadien 131, 2023 CanLIIDocs 1147, <https://canlii.ca/t/8w5gz>, consulté le 2026-02-17
CultureLibre.ca
Consignes pour le TP2 (proposition pour le travail final)
Olivier Charbonneau 2026-02-10
Pour le second travail pratique (TP2), vous devez produire un court texte (150 à 300 mots) dans lequel vous exprimez vos intentions concernant le thème que vous souhaitez explorer ainsi que la formule retenue dans le cadre du travail final. Ce texte sera déposé dans le forum du cours et les autres étudiants (ainsi que le prof!) du cours pourrons lire, commenter et proposer des suggestions pour votre travail.
Le travail final (et l’exposé oral) doivent proposer une réflexion sur les enjeux sociaux, culturels et politiques de la propriété intellectuelle et ses transformations contemporaines. Le contexte général est celui de la création web. Le TP2 consiste à formuler une intention concernant le travail final, tout en découvrant les fonctionnalités des forums web et les dynamiques de rétroaction et de partage entre collègues.
Il est proposé d’articuler cette réflexion autour des grands axes explorés lors du cours, comme certains des éléments suivants:
- Le régime général des droits: propriété, interdiction / consentement, exceptions, marchés, interactions…
- Les activités artistiques (théâtre, cirque, danse, spectacle et autres arts vivants), culturelles (livres et littérature, librairies, cinéma, télé, radio, arts visuels, etc.) ou créatives (p. ex.: logiciels et jeux vidéo).
- Les régimes juridiques spécifiques, tels le droit d’auteur, la confidentialité et les renseignements personnels, l’accès à l’information gouvernementale, le droit à l’image, la liberté d’expression, les législations artistiques (statut de l’artiste) et culturelles (agrément de librairies) , le respect des savoirs traditionnels …
- Les cadres juridiques privés, tels: la commercialisation des arts, de la culture et des produits créatifs, le libre accès, la gestion collective, le secret d’état ou commercial.
- Les cadres normatifs personnels, tels l’éthique et la déontologie.
- Les environnements ou les espaces publics possibles d’intérêt: le processus judiciaire, le gouvernement, l’université, l’école, la médecine et les hôpitaux, les données, les standards technologiques, les plateformes.
- L’interaction entre les créatrices, les organisations industrielles, les institutions et les citoyennes…
Il est approprié de formuler ce texte à la première personne du singulier. En ce qui concerne la structure de votre texte, les tous premiers mots doivent indiquer clairement quels éléments vous souhaitez explorer. Ensuite, vous devez cerner la ou les problématique(s), identifier les groupes concernés ou spécifier les technologies disruptives d’intérêt. Puis, vous devez indiquer clairement comment vous allez creuser la ou les éléments visés. Enfin, vous devez indiquer la formule souhaitée pour le travail, soit un travail solo de 15 pages, soit une autre formule à préciser.
Voici un exemple :
D’une part, la Loi sur le droit d’auteur interdit ce que la technologie permet. De l’autre, Internet constitue un moyen inégalé pour diffuser le riche patrimoine d’une collectivité. Je désire explorer le rôle des institutions dans la préservation des jeux vidéos créés au Québec. Pourquoi n’y a-t-il pas d’archive, de musée ou de bibliothèques du jeu vidéo ? Quels groupes seraient concernés ? Comment sont préservés les autres objets artistiques et culturels ?
Pour ce faire, je vais utiliser des bases de données comme Érudit.org, Cairn ou Sofia (via la bibliothèque de l’UQO) pour dénicher de la documentation pertinente et de haute qualité sur les questions de la préservation des logiciels ainsi que du rôle des institutions dans la préservation numérique. Je vais aussi lire les sites internet des associations des professionnels et compagnies de jeu vidéo pour déterminer leurs positions. Je vais tenter de trouver des projets de préservation de jeux vidéo dans d’autres pays pour analyser leurs bons coups.
Source : Olivier Charbonneau
Votre proposition doit être versée dans la rubrique appropriée du wiki du cours au plus tard le vendredi 18 20 février 2026 à 23h59.
Sur un autre ordre d’idées, chaque participant au cours devra proposer des commentaires à au moins 4 proposition de travail de collègues par le wiki. Il s’agit d’un élément constitutif des points de participation.
Suite à vos explorations et les échanges subséquents, vous devez mettre à jour votre proposition de travail final pour approbation avant la semaine de relâche.
CultureLibre.ca
Lectures pour la séance #6 (17 février 2026)
Olivier Charbonneau 2026-02-10
Lectures obligatoires
#Web #Droit Pierre Trudel, Le droit de la personne sur son image, 2020 25-1 Lex Electronica 353, 2020 CanLIIDocs 1423, <https://canlii.ca/t/xjt9>
#Web #Droit Commissariat à la protection de la vie privée du Canada, Trousse de présentation : initiation à la vie privée
Visionnez la présentation PPT et lisez les notes d’allocution
Source: Commissariat à la protection de la vie privée du Canada
Lectures optionnelles
#Web #Droit Commission d’accès à l’information, Plan stratégique 2023-2027, Québec, 22 p.
#Web #Enjeux Gouvernement du Canada, Guide pratique pour une stratégie de marketing d’influence réussie – Secteur de la mode et du vêtement, décembre 2024
#Web #Enjeux Comité directeur sur le marketing d’influence, Lignes directrices sur la divulgation, Normes de la publicité [Canada], 2020, URL: https://adstandards.ca/fr/ressources/marketing-dinfluence/
Non classé
Lectures pour la séance #5 (10 février 2026)
Olivier Charbonneau 2026-02-02
Lectures obligatoires
#Web #Droit Savoirs traditionnels autochtones, Institut de la propriété intellectuelle du Canada, S.D., Ottawa : Canada, https://ipic.ca/_uploads/5f90736db644a.pdf
#droit #web Choko, Maude (2022), De l’affaire du « petit » Jérémy à celle de la cigarette sur les planches de Québec : leçons à tirer pour l’exercice de la liberté artistique sur scène dans Volume 521 – Développements récents en matière de propriété intellectuelle et en droit du divertissement, Centre d’accès à l’information juridique.
J’ai préparé une version PDF de ce document disponible gratuitement dans Internet en 2023 pour faciliter le téléchargement. Cette utilisation d’un droit réservé au titulaire représente une mise en oeuvre de l’article 29.21 et 30.04 de la Loi sur le droit d’auteur.
Source: Centre d’accès à l’information juridique
Lectures complémentaires
#Web #Enjeux Déclaration des Nations Unies sur les Droits des Peuples Autochtones (A / RES / 61/295)
#Web #Enjeux Organisation Mondiale de la propriété intellectuelle (OMPI), Propriété intellectuelle relative aux ressources génétiques, aux savoirs traditionnels et aux expressions culturelles traditionnelles, 2020, Genève, p. 1-30 https://www.wipo.int/edocs/pubdocs/fr/wipo_pub_933_2020.pdf
#Web #Enjeux Desmarais, Laurence et Jérôme, Laurent « Voix autochtones au Musée de la civilisation de Québec : les défis de la muséologie collaborative ». Recherches amérindiennes au Québec 48, no 1-2 (2018) : 121–131. https://doi.org/10.7202/1053709ar
#Web #Enjeux Politique des Musées de la civilisation à l’égard des peuples autochtones, 2012
#Web #Enjeux Clara Delpas et Pierre William Johnson, «Protéger les savoirs des peuples autochtones», Le monde diplomatique, janvier 2014, p. 12-13
Pour accéder gratuitement au mensuel Français Le Monde Diplomatique, accès réservé à la communauté universitaire de l’UQO, connectez-vous à la banque de donnée Euréka et cherchez pour l’article (copiez-collez la référence bibliographique complète), attention il faut sélectionner « Toutes les périodes » pour la période avant de lancer la recherche: https://uqo.ca/biblio/ressources-electroniques/9686
bibliothèque offre un service d’aide par clavardage : contactez-les pour une assistance immédiate pour dénicher ce document
#Web #Enjeux Vinck Dominique, « « Avec les humanités numériques, les Suds vont se faire voler leurs patrimoines culturels. » », dans : , Humanités Numériques. La culture face aux nouvelles technologies, sous la direction de Vinck Dominique. Paris, Le Cavalier Bleu, « Idées reçues », 2016, p. 123-133. URL : https://proxybiblio.uqo.ca:2114/humanites-numeriques–9782846708883-page-123.htm
Pour accéder gratuitement au document précédent, accès réservé à la communauté universitaire de l’UQO, connectez-vous à la banque de donnée CAIRN et cherchez pour l’article (copiez-collez la référence bibliographique complète), attention il faut sélectionner « Toutes les périodes » pour la période avant de lancer la recherche: https://uqo.ca/biblio/ressources-electroniques/9557
La bibliothèque offre un service d’aide par clavardage : contactez-les pour une assistance immédiate pour dénicher ce document
#Web #Tech 10 conseils de référencement pour votre petite entreprise, Banque de développement du Canada
Veuillez noter que la BDC est une agence fédérale. Leur site offre une section sur le Marketing en-ligne. De plus, il est possible de télécharcher un guide de 23 pages intitulé Attirer de la clientèle et vendre en ligne que vous pouvez télécharger gratuitement en échange d’informations personnelles.
Idem pour la Société Canadienne des Postes, qui offre un guide de 40 pages pour vous renseigner sur la vente en-ligne, en échange de renseignements personnels
Source: BDC, SCP
#Web #Tech Comment fonctionne la recherche Google, lire la «version courte» et la «version longue» sur cette page: https://developers.google.com/search/docs/beginner/how-search-works
#Web #Enjeux Cadre de gestion de la communication gouvernementale, Québec (Québec) : Secrétariat à la Communication gouvernementale du Ministère du Conseil exécutif, [2019]
 Notes de ma présentation à l’École d’été « HNU6000 Humanités numériques : fondements disciplinaires Été 2026″ du CERIUM, en association avec le Centre de Recherche Interuniversitaire sur les Humanités Numériques (CRIHN), Université de Montréal, jeudi 28 mai 2026.
Notes de ma présentation à l’École d’été « HNU6000 Humanités numériques : fondements disciplinaires Été 2026″ du CERIUM, en association avec le Centre de Recherche Interuniversitaire sur les Humanités Numériques (CRIHN), Université de Montréal, jeudi 28 mai 2026.