Information et savoirs | Page 4
Document numérique Voix, données
Répertoires d’outils et données en humanités numériques
Olivier Charbonneau 2019-02-28
BigDIVA, Voyant-Tools, Cytoscape, RStudio… et vous, vous utilisez quel outil pour votre projet en humanités numériques ?
La sélection d’un corpus et d’outils d’analyse s’inscrivent dans les choix des chercheurs sur les plans épistémologiques, conceptuels et méthodologiques. L’univers numérique permet à tout-un-chacun de saisir de nouvelles opportunités de développer son propre cadre de recherche, une sorte d’environnement scientifique personnalisé. Et c’est bien là le problème au niveau (trans/multi/inter)disciplinaire : l’opportunité d’innover de par ses choix de sources et d’outils, quitte à rendre son projet unique, introduit divers glissements quant à la reproductibilité et la transférabilité de ses approches.
Dit simplement, nous vivons à une époque offrant des opportunités inégalées de recherche, au point où nous risquons de prendre de vue l’entreprise collective scientifique qui nous motive.
En ce sens, j’applaudis chaleureusement toute initiative de recensement et de description d’outils et de sources pour des projets en humanités numériques. En voici quelques-uns qui sont passés sous mon nez, n’hésitez pas à en ajouter dans la section commentaire de ce billet:
Open Methods du site DARIAH: un répertoire qui recense les méthodes et outils en humanités numériques. Vraiment intéressant comme catalogue pour des démarches intellectuelles.
DiRT:Directory is a registry of digital research tools for scholarly use.
Isidore, Votre assistant de recherche en Sciences Humaines et Sociales (sources, documents, sujets), surtout de France
De nos amies en Australie, le site HuNi pour les données artistiques et culturelles
Conférence Voix, données
droit + Intelligence artificielle: Conférence Les Cahiers de Propriété Intellectuelle
Olivier Charbonneau 2018-11-23
(BILLET EN COURS D’ÉCRITURE: ÉVÉNEMENT DU 23 NOVEMBRE – MISES À JOUR FRÉQUENTES AUJOURD’HUI)

Programme de la conférence Les Cahiers de Propriété Intellectuelle: droit + Intelligence artificielle
Je vous propose mes notes, j’assiste au colloque intitulé la droit + Intelligence artificielle: Conférence Les Cahiers de Propriété Intellectuelle
Première conférence: IA vue de l’extérieur
Marie-Jean Meurs, Coordonatrice d’HumanIA et Professeure, Département d’informatique (UQAM).
Apprentissage automatique: deux classes d’algorithmes,
- apprentissage supervisé: ensemble d’entrainement ou d’apprentissage; ensemble de test; caractéristiques; hypothèse pour une nième instance suite à l’analyse de l’ensemble test. Capacités de généralisation: quels ensembles d’apprentissage; quelles caractéristiques; quels algorithmes; quels usages => choix humains
- non supervisé: distance, caractéristique des « groupes »
Paul Gagnon, conseiller juridique ÉlémentAI
« La cité de l’intelligence artificielle » dans le MileX à Montréal…
Vu sur twitter ce matin: if it is written in python, it is machine learning; if it is written in powerpoint, it is artificial intelligence
Machines à tisser et le mouvement luddite/saboteur
Ne croit pas que la loi est à la remorque, nous avons le loisir d’anticiper, comprendre, comment le droit va s’arrimer à l’AI
Défis juridiques:
- Anonymisation des données (RGPD) pour utiliser le « moins possible » les renseignements personnels, comparaisons: actuaire doit agir en vertu de limites à l’utilisation de faits dans l’industrie de l’assurance
- RGPD: décision algorithmique, l’humain peut en appeler (transparence algorithmique), défaire la boîte noire technologique pour des raisons juridiques, la loi n’est pas à la remorque
- Droit d’auteur: génération d’oeuvres par des algorithmes; décortiquer les nouveaux cas avec les outils juridiques existants; dichotomie entre l’expression et l’idée
- droit sur les données: ne s’y attendait pas – le rôle des conditions d’accès imposées par les fournisseurs; données ouvertes (CC-BY vs. CC-NC), nuances technologiques qui ont une incidence en droit
Jocelyn MacLure, Professeur titulaire de philo, Université Laval
4e révolution industrielle, société post-travail, statut moral et juridique des agents algorithmiques: inflation sur la réflexion sur l’IA. On a besoin d’une perspective critique (au sens réfléchi, sobre, non-réactionnaire) pour mieux comprendre la situation.
Harari: Homo deus, 21 leçons pour le 21e siècle = révolutions sociales = on doit développer une autre approche
Citation:
Machines will be capable within 20 years to do any work a human can do, Herbert Simon pionnier de l’IA en 1965
Enjeux éthiques importants, il faut considérer les bénéfices
- Rendre la justice plus accessible, efficace, juste
- Santé: bénéfices attendus sont importants mais les risques persistent (ndlr, voir ce texte dans Le Devoir ce matin)
- Accidents de la route
Enjeux éthiques
- responsabilité [civile] des décisions ou actions des agents automatisés, lien de causalité, sommes-nous bien outillés avec les concepts et approches existantes.. concepteur de l’algorithme, l’utilisatrice…
- Transparence des algorithmes, devoir d’explicabilité (sic) et de justification des concepteurs (retracer les étapes de prise de décision pour obtenir un résultat donné, les raisons du jugement de la machine sont inaccessibles surtout en apprentissage profond non supervisé). Probablement l’enjeu éthique le plus important. Cas de Predpol. Cas d’un prêt bancaire. Cas d’une université pour l’admission dans un programme. Cas d’un département des ressources humaines pour faire un premier tri. Cas de charte, de discrimination, droitt à l’égalité des chances => comment opérationaliser le devoir éthique de transparence ? Doit-on imposer un devoir de justifications ? débats en recherches… biais des algorithmes
- Vie privée: texte dans Le Devoir. Droit à l’intériorité, ce droit d’avoir des opinions personnelles et de décider si on les diffuse… si un algorithme prédit mon opinion, contrevient-on à mon « droit d’intériorité »
- Droit du travail: distribution de la richesse, justice au travail, est-ce que nos politiques fiscales et sociales et scolaires sont bien calibrées pour redistribuer les richesses engendrées par l’IA ? Paupérisation exacerbée des démunis.
Réflexion éthique et réflexion avec les juristes et des technologues. Qu Québec: prise de conscience par l’entremise de la déclaration de Montréal sur l’IA responsable, qui sera dévoilée le 3 décembre prochain.
La question qui m’anime suite au panel: les algorithmes sont des outils, vivons nous un moment similaire à l’écriture du code civil au début du 19e siècle: observons-nous un nouveau modèle pour le droit (où ni les juges/précédents, ni un texte-code-autoritaire mais un algorithme stipule le droit) ou simplement l’accélération de ce qu’on fait ? Est-ce que l’accélération mènera à un système juridique homothétique (qui résistera à l’accélération) ou mutera-t-il au delà des systèmes actuels (distinction entre civilisme, common law, droit religieux… lex machina?).
Deuxième panel: IA et PI
Tom Lebrun, doctorant à l’Université Laval
Deux arguments:
- le droit doit tenir compte de l’appropriation des données: apprentissage machine: apprentissage statistique == du déductif à l’inductif (doctrine citée: Dominique Cardon sociologue 2018; Sobel 2017; Mc Cormack 2014; Guadamuz 2018; Shank & Owens 1991) – Jurisprudence: Apple Computer c. Mackintosh Computers 1987; Éditions JCL…. réflexe est de se dire qu’apprentissage machine = appropriation (mais il y a CCH)
- L’IA est un outil. L’auteur qui l’utilise doit être considéré comme titulaire. $ possibilités: IA comme auteur; IA comme travailleur que l’on sollicite; ne connaître aucun auteur; IA comme outil (celle que Lebrun privilégie). Jurisprudence: Geophysical Service Incorporated c. Encana 2016; Thomson c. Robertson 2006. Est-ce que l’oeuvre est suffisamment nouvelle? Cinar c. Robinson 2013;
(Modèle formel d’un neurone artificiel)
Caroline Jonnaert, juriste et doctorante, Université de Montréal
Sujet de thèse: Encadrement des créations par apprentissage profond dans le droit d’auteur; Une image vaut mille «maux»; un outil qui n’est pas comme un appareil photo pour le photographe; les rôles s’inversent
Problématiques en droit d’auteur
- processus créatif (c.f. la présentation de Tom Lebrun)
- résultante créative: réflexion tardive au Canada; consensus étranger autour du régime centré sur l’empreinte créatrice humaine; divers aménagements proposés
Critères: originalité? auteur… humain?
Ouverture sur les constats de Azzaria dans les CPI 30(3)
Réflexion: est-ce que les paramètres des outils constitue une sélection et l’arrangement de faits, qui amène une protection? Quid pour la sélection et l’arrangement du corpus source analysé par l’outil
Louis-Pierre Gravel, avocat chez Robic, brevets
Big data étude d’IBM; percent of time spent processing & collecting data études McKinsey & Bloomberg; The Economist prétend que les données sont la ressource ayant le plus de valeur
(Notions de base en IA) Types d’IA: descriptive; diagnostique; prédictive; prescriptive (prévenir ou reproduire)
Global AIO Talent Report 2018, ElementAI; Indeed.com
Protection par brevet de l’IA (outils ou résultats)
Étude de Warin, Le Duc, Sanger sur les brevets déposés en IA,
- “Mapping Innovations in Artificial Intelligence Through Patents: A Social Data Science Perspective” (Warin, T., Le Duc R., Sanger W.), Proc. Int. Conf. Comput. Sci. Comput. Intell. (CSCI), 2017.
Étude de l’OCDE de 2017 STI Digital Scoreboard : domaines de l’IA. Voir aussi le rapport de (NDLR: 2018 sur les emplois de l’avenir)
Critères pour un brevet: une invention! (ou une amélioration)
- La nouveauté: première du genre
- L’ingéniosité ou rapport inventif; critère de la non-évidence
- L’utilité: fonctionnalité de l’invention
Non-brevetable: découvertes ou théories scientifiques; formules mathématiques; algorithmes
Inventions mises en oeuvre par ordinateur: n’ajoute rien et n’enlève rien à la brevetabilité d’un appareil ou d’un procédé. L’utilisation de l’ordinateur n’est pas suffisante
Deux catégories en IA:
- Avancement dans les technologies de l’IA
- Nouveaux appareils ou procédés faisant appel à l’IA; la vision de l’IA comme outil
Voir le texte de Camille Aubin dans Les CPI 30(3)
Panel 3: IA + droit civil
Nicolas Vermeys, professeur à la Faculté de droit, Université de Montréal
La responsabilité civile: agent autonome; agent intelligent. Col bleu tué dans l’usine Volkswagen; accident avec une voiture autonome
1457 CcQ responsabilité civile: faute, dommage et lien de causalité. Réparer ce préjudice.
Chaîne d’intervenants, 6 individus : Concepteur; programmeur; entraîneur; propriétaire; propriétaire de la base de données; utilisateur
Qui est responsable ? Dépend:
- type d’IA: agent intelligent ou autonome (aspirateur ou voiture?)
- de la qualification de la relation entre l’IA et son utilisateur: propriété, agence/mandat, gardien
Régimes juridiques possibles applicables à l’IA
- Responsabilité pour le fait (autonome) des biens… au Québec, le CcQ 1465: le gardien d’un bien est tenu de réparer le préjudice causé par le fait autonome (nécessite une nouvelle conceptualisation de ce dernier point), absence d’intervention humaine directe; mobilité ou dynamisme… et qui est le « gardien » de l’IA (notions de surveillance et contrôle) parmi les 6 intervenants identifiés
- Accorder la personnalité juridique aux agents autonomes… intelligence? Indépendance/initiative? Accordée à des objets? Refuser la personnalité juridique parce que: pas de patrimoine, pas raisonnable – est-ce qu’une IA est douée d’intelligence? et la raison, un autre niveau… exemple de Rainman.
- Régime inspiré de la responsabilité pour les animaux. Art. 1466. Propriétaire vs. le gardien.
- Régime inspiré de la responsabilité pour les esclaves. Wright c. Weatherly, 15 Tenn. (7 Yer.) 367, 378 (1835)
Quelle approche adopter? Les avocats sont de mauvais oracles (« The blind are not good trailblazers »), cf. juge Easterbrook «Cyberspace and the law of the Horse» (1996) Uni. of Chicago Legal Forum 207
Antoine Guilmain, docteur en droit UMontréal + Paris 1, Fasken
William Deneault-Rouillard (en tandem)
IA + Contrat (excluant la blockchain)
Ça va régler tous les problèmes // Tout ou rien… fausse route
- Nouveaux modèles d’affaires: économie numérique. La donnée est une denrée. Contrat électronique, « I agree » sans lire, diarrhée contractuelle, gratuité et consommation (contrats d’adhésion, légalité), données comme contrepartie contractuelle, consentement…
- Application concrète de l’IA tout au long du cycle contractuel, recherche de co-contractants (marketing comportemental, ajustement de l’offre, embauche et analyse de candidatures), rédaction du contrat, compréhension et formation du contrat (recherche factuelle sur le cocontractant et quantification probabiliste du risque, adhésion: plug-in PrivacyCheck sur les conditions de contrats sur la vie privé ), gestion et analyse des contrats (reconnaissance automatique des types de contrats, recherche algorithmique de contrats….) (outil kira de Fasken), litige et interprétation contractuels (outil predictice), exécution du contrat
- Défis conceptuels: propriété des données (database protection/encryption, data protected by copyright, data protected by trade secrets, data protected by privacy and data protection law) source: R. c. Stewart 1988 – pas de vol car pas de propriété sur données; arrangements contractuels; responsabilité civile contractuelle (multiplicité d’acteurs et attribution contractuelle; exonération art. 1613 CcQ; protection du consommateur; normalisation des contrats – ISO)
Rapport Villany: garder la main
Pierre-Luc Déziel
Dans Les CPI (30)3.
Ce que disent les données lorsque les IA les font parler. Projet « myPersonality » Michal Kosinski
Limite ontologique, opérationnelle (Ewert c. Canada, 2018 SCS 2018), structurelle…
Panel 4: Domaines d’application
Marc Lacoursière (prof AED, U Laval), Ivan Tchotourian (prof ), Ann-Shirley Lebel (étudiante)
Défi de l’encadrement juridique de l’intelligence artificielle dans l’industrie bancaire et des valeurs mobilières
Céline Castets-Renards, prof. Journalisme
Dans Les CPI 30(3)
Outils aidant les journalistes. Outils se substituant aux journalistes. Outils qui rédigent pour les journalistes.
Enjeux:
- Questionnement lié à l’emploi: outils qui rédigent pour le journaliste. Stagiaires, pigistes, jeunes journalistes: quelle nouvelle génération de journaliste?
- Métier même de journaliste: déontologie et professionnels. Vérification des faits, recoupements, interroger les gens, investigation… l’outil peur remettre en cause ces facteurs fondamentaux de la profession. Pluralisme et la diversité des médias, aurons-nous tous les mêmes information, consensuels, convergence de l’information. Protection des sources
- Liberté de la presse, d’information, d’expression. Les outils ne sont pas neutres. Quelles données seront utilisées et par quels systèmes aboutirons-nous aux articles
Transparence algorithmique: pas créé par le RGPD. Art 22 pas de décision automatique algorithmique sans droit d’appel – à lire avec les art. 13 à 15 pour la logique sous-jacente. L’art. 22 n’introduit pas l’explication individuelle. Il faut regarder comment les états ratifient le RGPD. Le texte Français propose un droit à l’explication pour les acteurs publics.
Jie Zhu
Justice prédictive
Data analytics: descriptive / diagnostic analysis => predictive analytics => prescriptive analytics
Droit Internet Standards
Est-il possible de « designer » le droit ?
Olivier Charbonneau 2018-11-05
Le chercheur est souvent appelé à identifier et expliquer ses choix intellectuels. En droit, je considère que le premier exercice réflexif consiste à comprendre à quelle famille intellectuelle l’on s’identifie. Je crois qu’il en existe trois principales familles intellectuelles: naturaliste, positiviste et pluraliste. Les naturalistes considèrent que la source du droit découle de la condition naturelle des humains et s’exprime surtout dans les grandes déclarations à saveur constitutionnelles, comme les droits fondamentaux, etc. Les positivistes considèrent que le droit provient de l’écrit découlant du processus législatif et jurisprudentiel, l’analyse positiviste est un moyen de découvrir le droit édicté. Les pluralistes, quant à eux, considèrent qu’il faut observer les institutions, organisations et agents d’un système socioéconomique pour comprendre le droit qui les gouvernent, bien au-delà de l’ordre régalien.
Personnellement, je suis franchement dans le pluralisme, d’autant plus que les objets qui m’intéressent, les documents et les communautés qui les utilisent, se trouvent plus souvent qu’autrement numérisés. Il est plus pertinent d’utiliser l’outil pluraliste dans ce contexte car j’observe l’émergence de droits via les relations contractuelles.
Il y presque deux ans, j’ai collaboré avec des professeurs en design et en informatique afin de voir si l’on pourrait partir de la théorie pluraliste en droit, comme cadre théorique et conceptuel au sens large, afin d’y greffer une méthodologie en design participatif (participatory design, spécifiquement le requirements engineering approach). Le contexte technologique consiste à identifier des métadonnées juridiques afin de bâtir un système interopérable, évolutif et ouvert dans la chaîne de diffusion culturelle, comme en utilisant des technologies de chaînes de blocs et des algorithmes apprenants. Cette approche peut s’appliquer à divers environnements, comme les bibliothèques ou les réseaux sociaux, où évoluent divers agents et objets à l’étude.
Je suis tombé par hasard sur ces notes et je partage avec vous les sources qui m’ont été suggéré à l’époque, voir ici-bas. Je crois que certaines conceptualisation du droit, surtout celles de l’école pluraliste (systémique, cybernétique, réseaux) permettent aux agents de designer un régime juridique, tout comme elles peuvent co-concevoir un système technologique. Il s’agit, bien sûr, d’un domaine de recherche encore relativement vierge !
Sources:
Muller, M. J. Participatory design: The third space in HCI. In J. A. Jacko and A. Sears (Eds.), The Human Computer Interaction Handbook: Fundamentals, Evolving Technologies and Emerging Applications, Lawrence Erlbaum, Mahwah, NJ, 2002, 1051–1068.
Muller, Michael J., Sarah Kuhn. 1993. Participatory design. Commun. ACM 36, 6 (June 1993), 24-28. DOI=http://0-dx.doi.org.mercury.concordia.ca/10.1145/153571.255960
Vines, John, Rachel Clarke, Peter Wright, John McCarthy, and Patrick Olivier. 2013. Configuring participation: on how we involve people in design. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI ’13). ACM, New York, NY, USA, 429-438. DOI: https://doi.org/10.1145/2470654.2470716
Critique France Internet Livre et édition
Mon ami Sartre
Olivier Charbonneau 2018-10-22
 Il me restait quelques moments avant de terminer ma journée, quelques minutes tout au plus, juste assez pour repasser les missives reçues par courriel pour m’assurer que je n’ai pas complètement négligé ma correspondance. Et je suis tombé sur ce message, sans mots autre qu’un hyperlien, de ma propre plume, à moi même.
Il me restait quelques moments avant de terminer ma journée, quelques minutes tout au plus, juste assez pour repasser les missives reçues par courriel pour m’assurer que je n’ai pas complètement négligé ma correspondance. Et je suis tombé sur ce message, sans mots autre qu’un hyperlien, de ma propre plume, à moi même.
Il s’agit du message parfait pour meubler ces instants où le soleil d’automne vacille vers le crépuscule. Le voici:
http://figura-concordia.nt2.ca/appel-raconter-linternet
Ah oui, il s’agit d’un appel de communication de mes collègues en littérature – un domaine que je considère comme prioritaire pour partager mes résultats de recherche en droit d’auteur numérique… dans l’appel, une phrase en particulier m’accroche, une référence directe à Jean-Paul Sartre:
Cette journée d’étude vise à réfléchir à la présence du numérique dans le roman et à ses implications sur l’imaginaire contemporain. Les interventions, que nous souhaitons fondées sur des études de cas, chercheront à émettre quelques hypothèses sur ce que « peut » la littérature, pour reprendre la célèbre formule de Sartre, lorsque confrontée aux effets sémiotiques ou rhétoriques des innombrables dispositifs, applications, réseaux et logiciels qui balisent désormais le quotidien.
Tiens, une célèbre formule de Sartre ? Quid… Mon le duo Google-Wikipedia me lancent sur la trace de l’essai Qu’est-ce que la littérature ? que je retrouve sous mes pieds (oui, oui, je travaille au 5e de ma bibliothèque universitaire et le livre est classé au 4e).
Il faut dire que le moment s’est envolé et j’ai réellement manqué mon train… assis sur ma chaise, je savoure cette édition ancienne, éphémère, où chaque page semble sur le point de se sublimer en nuage de poussière !
Je trouve beaucoup de perles, fragments de pensées attrapées par butinage paresseux. Je saute à la section « Pour qui écrit-on ? » de l’essai en question et je découvre ces mots, à la page 128-9:
L’écrivain consomme et ne produit pas, même s’il a décidé de servir par la plume les intérêts de la communauté. Ses oeuvres restent gratuites, donc inestimables ; leur valeur marchande est arbitrairement fixée. […] Au fond on ne paie pas l’écrivain : on le nourrit, bien ou mal selon les époques. Il ne peut en aller différemment, car son activité est inutile : il n’est pas du tout utile, il est parfois nuisible que la société prenne conscience d’elle-même. Car précisément l’utile se définit dans les cadres d’une société constituée et par rapport à des institutions, des valeurs et des fins déjà fixées.
Je viens de trouver ma lecture de chevet pour les prochaines semaines…
Conférence Histoire et sciences sociales Montréal
Notes: Conférence d’Yves Gingras – Chaire Lexum
Olivier Charbonneau 2018-10-16
Conférence d’Yves Gingras – Chaire Lexum
Titre: De l’Homo Faber à l’homo Techo-logicus ou la fin de la nature
Approche: anthropologie philosophique (énoncé d’une thèse générique sur l’humanité)
Énoncé de thèse: humain est un être contre-nature anti-nature produit le plus paradoxal de la nature et les devenu un homo techno-logicus. Une critique de la critique de « la technique »
transformation des sciences à travers l’histoire humaine
Inspiration des années 1960: Ellul; Heidegger sur la technique. Selon Gingras, l’erreur fondamentale de ces discours est de dissocier l’humain de la techne.
Antiphon, 5-4e siècle avant J.C.: « là où la nature nous dominait, technès nous rend vainqueur »
Du grec, au latin, au français:
- technès: art, artisan…
- logos: raison, discours, langage…
- Techno-logie: théorie des techniques (Aristote et sa théorie des cinq machines simples: roue, coin, levier, vis, treuil, c.f. Questions de mécanique, 3-2e siècle)
- Technique à distinguer de la technologie
Technique contre technologie: le livre de Jacques Ellul: Le bluff technologie… oui, mais la compréhension des mots change avec le temps.
Illustration de sa thèse Historique de la technè par des exemples
- Texte hermétique, 4e siècle: L’homme maître de la nature?
- Francis Bacon 1620: Les secrets de la nature se révèlent plutôt sous la torture des expériences que lorsqu’ils suivent leur cours naturel
- Descartes 1637: « nous rendre comme maîtres et possesseurs de la nature »
- Réponse romantique: Goethe aux rationalistes
- L’oeil instrumenté: le télescope contre l’oeil nu… par la pensée… matérialisée (Louis de Broglie: mécanique ondulatoire, 1924) Se développe une vision purement mathématique appliquée à des données == abstraction par analogie == microscope électronique 1931………
- Manipuler la matière: de 1897 et l’électron jusqu’à 1945 bombe atomique
- Manipuler la Terre: changement climatique, fracturation, …
- Manipuler la vie
La vie sans les humains… conclusion: l’humain est la première espèce contre-nature
Flore laurentienne de Marie-Victorain: reprise en charge des maisons par la nature dans un univers post-humain où l’anthropocène émerge de la révolution industrielle et confirme sa thèse
Communautés Conférence France Histoire et sciences sociales Lettres Montréal
Pistes pour se lancer dans le réseau
Olivier Charbonneau 2018-09-28
N’hésites pas à ajouter des pistes supplémentaires dans les commentaires de ce billet ou contactez-moi pour que je puisse renseigner cette liste.
CultureLibre.ca Logiciel à code source libre
Cours ouvert sur Weka
Olivier Charbonneau 2018-09-15
 Cet automne, je vais plonger dans l’univers des algorithmes apprenants et des données massives par le biais de ce cours en-ligne ouvert traitant de Weka. Il s’agit d’un logiciel à code source libre développé par une université en Nouvelle-Zélande. Weka semble être exactement le genre d’outil qui devrait figurer dans la trousse du bibliothécaire (post)moderne…
Cet automne, je vais plonger dans l’univers des algorithmes apprenants et des données massives par le biais de ce cours en-ligne ouvert traitant de Weka. Il s’agit d’un logiciel à code source libre développé par une université en Nouvelle-Zélande. Weka semble être exactement le genre d’outil qui devrait figurer dans la trousse du bibliothécaire (post)moderne…
Si vous êtes dans la région de Montréal, on pourrait tenir des sessions de co-étude une fois par semaine, contactez-moi si ça vous intéresse !
Accès libre Bibliothécaire Conférence Europe Histoire et sciences sociales Lettres
Notes de la conférence d’ouverture de prof. Alan Liu #DHN2018
Olivier Charbonneau 2018-03-07
 J’ai l’énorme plaisir de participer à la Digital Humanities in Nordic Countries Conference à Helsinki cette semaine. J’y présente demain (jeudi après-midi) ma thèse doctorale, financée en partie par la Foundation Knight. Les thèmes de cette troisième version de cet événement sont: « cultural heritage; history; games; future; open science. »
J’ai l’énorme plaisir de participer à la Digital Humanities in Nordic Countries Conference à Helsinki cette semaine. J’y présente demain (jeudi après-midi) ma thèse doctorale, financée en partie par la Foundation Knight. Les thèmes de cette troisième version de cet événement sont: « cultural heritage; history; games; future; open science. »
Suivez la conférence sur Twitter grâce au mot-clic #DHN2018.
La conférence a été précédée par un séminaire sur l’utilisation d’outils de traduction simultanée dans le processus créatif. J’y reviendrai peut-être…
Je désire offrir mes notes de la communication d’ouverture du professeur Alan Liu, portant les protocoles de travail ouverts et reproductibles en humanités numériques. Il divise sa présentation en trois parties: la vue au rez-de-chaussée ; la vue à la cime des montagnes et la vue stratosphérique. Trois points de vue du même phénomène pour mieux saisir les défis à saisir.
Avant tout, Liu définit les humanités en citant la loi habilitante du National Endowment for the Humanities aux USA (National Foundation for the Arts and the Humanities Act, 1965). En réalité, il articule « humanities » en cinq vecteurs théoriques: les humanities au sens classique platonique de la rhétorique, de la logique et de la grammaire; des social sciences; des science (au sens de STEM; et des creative & performing arts. Ces cinq vecteurs définissent les forces à l’oeuvre pour les humanités numériques. Il indique que les humanités sont essentielles dans le concert des disciplines intellectuelles, il collabore à l’initiative 4humanities.org pour en faire la promotion.

I. Vue du rez-de-chaussée
Prof. Liu présente son projet qui emploie l’outil DFR Browser pour son projet WhatEveryone1Says. Afin de proposer une méthode qui est ouverte et reproductible, Liu propose deux étapes, suivant cette structure:
A. Un système de gestion du cycle de vie virtuel (virtual workflow manager)
Utilisant un « Jupyter » notebook comme outil, l’équipe de Liu peut moissonner (scrape), gérer la provenance et le cycle de travail (workflow), les processus analytiques (analytical processes of topic modelling and word embedding), et l’interprétation. Sans le dévoilement de ces éléments, les humanités numériques ne peuvent espérer devenir une science ouverte et reproductibles.
B. Provenance
L’équipe de prof. Liu utilise des bibliothèques JSON pour l’identification du corpus et la confection de notes d’accès, les points de données (data nodes along the wy: raw data, processed data, scripts). Le tout est consigné dans une base de donnée MongoDB.

II. Vue à la cime des montagnes
Dans ce cas, il est essentiel pour un cycle de travail ouvert de se formaliser. Liu utilise « Wings » qui est une ontologie OWL. Il mentionne aussi le protocole W3C PROV (PROV-O; PROV-datamodel; PROV-OWL).
III. Vue stratosphérique
Liu cite la page 6 du rapport suivant: Our cultural commonwealth: Report on the American Council of Learned Societies on Cyberinfrastructure (2006). Liu cite aussi son rôle au sein de la nouvelle revue Journal of Cultural Analytics, basée à l’Université McGill à Montréal. Il cite aussi un article intitulé « Towards an automated data narrative » par Gil et al. dans Communications of the ACM.

Questions
J’ai posé la dernière quesiton à prof. Liu, à propos du rôle des bibliothèques et des bibliothécaire dans son « nouveau modèle » des humanités. Il précise que nous devons déconstruire le cycle de vie d’un projet pour identifier tous les microdocuments générés. Il faut aussi analyser les environnements numériques de travail: ceux de développement, de production, d’infonuagique. Il faut aussi bâtir des dépôts institutionnels et des dépôts de code informatique.
Bibliothécaire CultureLibre.ca Information et savoirs
Prolégomènes à un jeu sur le libre accès
Olivier Charbonneau 2018-02-19
Depuis que Marc Larivière, Vincent Larivière et moi avons travaillé sur une collection de Microfiches sur le Libre Accès, nous avons décidé de poursuivre la collaboration en développant un jeu vidéo récupérant le magnigique concept graphique.
Dans ce billet, j’ai recours au féminin ou au masculin un peu aléatoirement. Nous ne savons pas encore comment nous allons genrer les personnages. Étant donné que la population universitaire est plus féminine que masculine, et bien, je fais place aux dames.
L’idée consiste à offrir une oeuvre numérique que les bibliothèques universitaires et de Cégep (collège pré-universitaire au Québec) peuvent diffuser sur les écrans tactiles déployés en leurs lieux. Nous désirons bâtir un jeux plurilingue (français, anglais, allemand… et plus!) qui traite d’une manière ludique d’un sujet complexe mais très important pour l’avenir de la science.
D’ailleurs, nous sommes à la recherche de financement et sommes à établir des solutions de visibilité à des organimes sympatisants à notre travail. Je suis chercheur et fonctionnaire, mon salaire est assuré par la bienveillante Université Concordia. Par contre, mon associé, Marc Larivière, jeune papa de son état, ne bénéficie pas d’un tel support…
Après plusieurs réunions très stimulantes, Marc et moi avons développé un concept de jeu. Une partie devrait durer 10 à 15 minutes, l’idée est qu’une utilisatrice passant dans une bibliothèque interagit avec un écran tactile pour se changer les idées…
Le personnage principal du jeu, l’avatar de la joueuse, est une doctorante ayant complété son examen de synthèse.
Le jeu se déroule en trois phases.
La première phase du jeu consiste en « l’écriture » et devrait durer de 2 à 4 minutes. Nous anticipons une style de jeu comme « Tetris » (jeu compulsif) où la joueuse est appelée à augmenter son « nombre de mots (l’infâme word count qui hante tous les thésards). Étant donné la charte graphique des microfiches, nous jouons sur l’analogie de la molécule pour représenter l’action d’écrire ou pour l’accumulation de données dans le cadre de ses recherches (donc, fonctionnellement, de créer du savoir nouveau par l’analogie d’une nouvelle molécule).
Une fois assez de mots/données (ou molécules) accumulés, la thésarde (T) est appelée au bureau de sa directrice de recherche (DR). Débute ainsi la seconde phase, celle de la conversation. Nous ne sommes pas encore entièrement certains de comment la conversation avec la DR se déroulera, mais la tentation est forte de voir la DR imposer à T une suite pour diffuser ses recherches. Spécifiquement, la DR imposerait à T de proposer un article à une revue prestigieuse (en accès fermé) avec celle-ci (la DR) comme première auteure.
Suite à cette séquence (qui devient un peu la mission de la joueuse), la seconde phase dure de 8 à 12 minutes. T est appelée à se promener dans un labyrinthe (en réalité, les corridors universitaires) et de parler à d’autres chercheur.e.s ou épier des conversations. Elle pourra aussi effectuer des recherches sur un moteur de recherche pour découvrir des informations sur les personnes ou les objets de son environnement.
L’objectif de cette phase est d’accumuler des objets-connaissance en lien avec sa situation. Nous avons en tête le style de jeu de Zelda lorsque Link se promène dans un village – sauf en plus dynamique (certaines versions de Zelda sont assez fastidieuses dans les séquences de d’exploration de village).
Un des point de cette étape consiste en la découverte des personnages de l’université. Tous sont chercheurs, certes, mais tous n’ont pas le même statut. Les professeurs, par exemple, peuvent être adjoints (en probation qui dure 5 ans, dont timides et serviables pour les profs plus séniors), agrégés (permanents mais encore « juste » des profs) et titulaires (reconnus comme experts par leurs pairs). Nous ne croyons pas avoir recours aux profs émérites (à la retraite). Il y a aussi les post-doctorants (un contrat de 1 à 3 ans où un chercheur est appelé à bâtir son programme de recherche et de développer ses talents d’enseignement en vue de l’obtention d’un poste de prof régulier). Les post-docs jouissent d’une autonomie relative assujettie à une grande précarité. Viennent ensuite les bibliothécaires (comme moi) et les agents de recherche (on risque de les couper ceux-là, ça fait beaucoup de personnages). Outre ces rôles liés à la structure départementale (bureaucratique) universitaire, il y a des rôles fonctionnels liés à la discipline (ou champ de la connaissance). Ainsi, tous les chercheurs peuvent être membre du comité scientiique d’une revue dans un domaine/discipline donné (mais ce rôle est plus probable aux profs ayant un statut plus ancien). Il faudra réfléchir à la distinction/dynamique entre le statut départemental (bureaucratique) et le statut dans une discipline donnée…
Les personnages ont donc un statut à l’université en fonction de leur poste. Nous allons jouer sur les stéréotypes de genre de d’âge pour brouiller les cartes (tiens, est-ce que cet homme d’âge mûr au teint de peau blanc est réellement un prof titulaire ou un bibliothécaire?) et ajouter un élément d’incertitude. C’est que, dans la phase conversation, la joueuse obtiendra des informations contradictoires grâce à ces interactions avec les autres personnages. Par exemple, certainnes pourrait lui dire de ne pas publier dans cette revue… ou de se méfier d’un tel… ou qu’il est plus aviser de proposer une communication à un congrès avant de publier… ou de ne pas mettre le nom du DR sur son article… qui croire? quoi faire?
Quant à la discipline (ou domaine ou champ de la connaissance), c’est plus délicat. Souvent, les chercheurs effectuent leurs travaux au sein de sociétés savantes et nourissent leur discipline de leurs travaux. Il y a plusieurs rôles ou fonctions au sein de sociétés savantes mais le plus important est celui où un chercheur est appelé à évaluer le travail des autres : évaluateur d’un comité scientidique d’une revue; évaluateur des communications à un congrés, etc. On va s’amuser à développer une fausse discipline !
Une autre option à la phase « conversation » consiste à chercher via des outils numériques des informations à propos autres personnages (une telle est sur le comité scientifique de cette revue) ou des objets (quelle est la politique en accès libre de cette revue). Nous pensons à établir de fausses revues et à créer des notices SHERPA/RoMÉO. Nous pensons à créer un faur réseau social pour lister les personnages du jeu.
Finalement, nous arrivons à la troisième et dernière phase, celle de la publication. La joueuse doit effectuer un choix pour la diffusion de sa molécure-texte: quelle avenue choisir; qui lister comme auteur; quoi faire avec la version pré ou post éditée… Il s’agit du moment où la décision est prise et où la partie se termine. Ou pas…
En réalité, il y a une logique de rétroaction basée sur les données générées par une partie du jeu. Nous pensons identifier certaines mesures intrinsèques à la partie et à la joueuse. Par exemple, il sera possible d’accumuler des « mots » (molécule), de l’argent (revenu de contrats de recherche), de l’impact social et des « points citations académique » (réputation, impact académique qui se distingue de l’impact social). Tous les personnages vont avoir un discours (ou message) en lien avec ces mesures. Par exemple, la bibliothécaire portera le message de publier en libre accès, ce qui aura un impact positif sur l’impact social mais pas nécessairement sur les autres éléments de mesure. Les valeurs par défaut de toutes les mesures seront établies lors de la conversation entre T et sa DR.
Une autre idée consiste à proposer à la joueuse d’effectuer une seconde partie. Par exemple, sont texte envoyé à une revue prestigieuse est rejeté et celle-ci doit entamer une nouvelle phase d’écriture (phase 1). La rencontre avec sa DR sera modulée en fonction de son/ses choix précédent(s).
Il serait aussi possible d’accumuler des statistiques (par exemple, via le standard de données COUNTER lié à l’utilisation de ressource électroniques en bibliothèques) sur toutes les parties pour comparer les choix entre les joueuses et, éventuellement, même comparer les institutions! Mais là, ça va nous prendre tout un budget….
In fine, je vous propose nos brouillons établis lors de la réunion hebdomadaire de la semaine dernière:
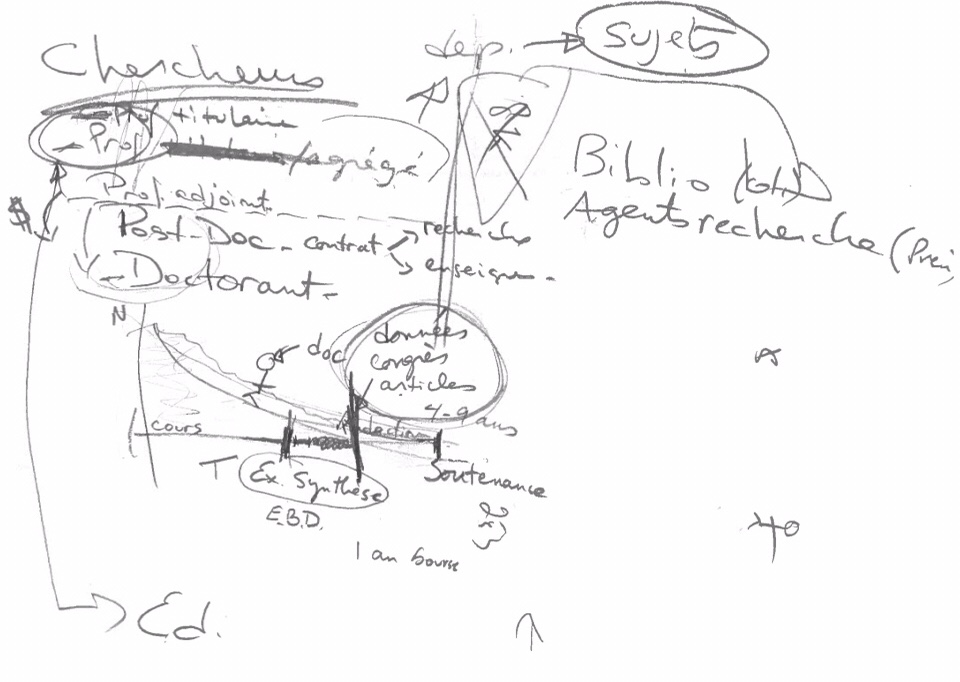
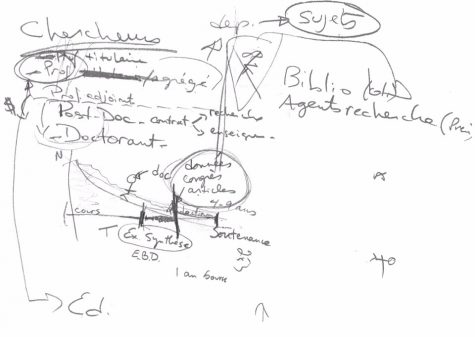
1. Séquence de jeu:
Sur cette première page (ici-bas), nous identifions les trois grandes phases du jeu et certains personnages. En jaune, à l’instar de la collection de microfiches sur le libre accès, se trouve l’avatar de la joueuse: la thésarde et personnage principal. En noir, divers personnages secondaires (du jeu), des profs titulaires (PT), profs adjoints (PA), des éditeurs de revues (Éd.) et d’autres doctorants (PD).

2. Personnages:
Dans la seconde image (ici-bas), nous explorons la typologie des personnages. Par ailleurs, j’ai tenté de représenter la distinction entre un département universitaire et un champ disciplinaire. Un des rôles de l’université consiste à structurer le travail des chercheurs en départements qui jouent un rôle fonctionnel très typé et lié à la bureaucratie universitaire, tout en permettant assez de latitude pour le développement de disciplines de la pensée (des profs de sociologie ou de cinéma peuvent effectuer de la recherche en ludologie par exemple). Finalement, Constatez vers le bas un plan cartésien à un quadrant, où j’explique le nombre total de doctorants qui « survivent » à un programme à travers le temps. Plusieurs débutent leur programme mais peu se rendent à la soutenance. Je situe le personnage principal du jeu entre l’examen de synthèse (là où le projet de thèse est accepté après la scholarité doctorale) et la soutenance (la fin réelle du programme de doctorat, où le comité de recherche, dont la directrice de recherche est membre, évalue le travail accompli avant que la thèse ne soit acceptée puis diffusée par l’université).
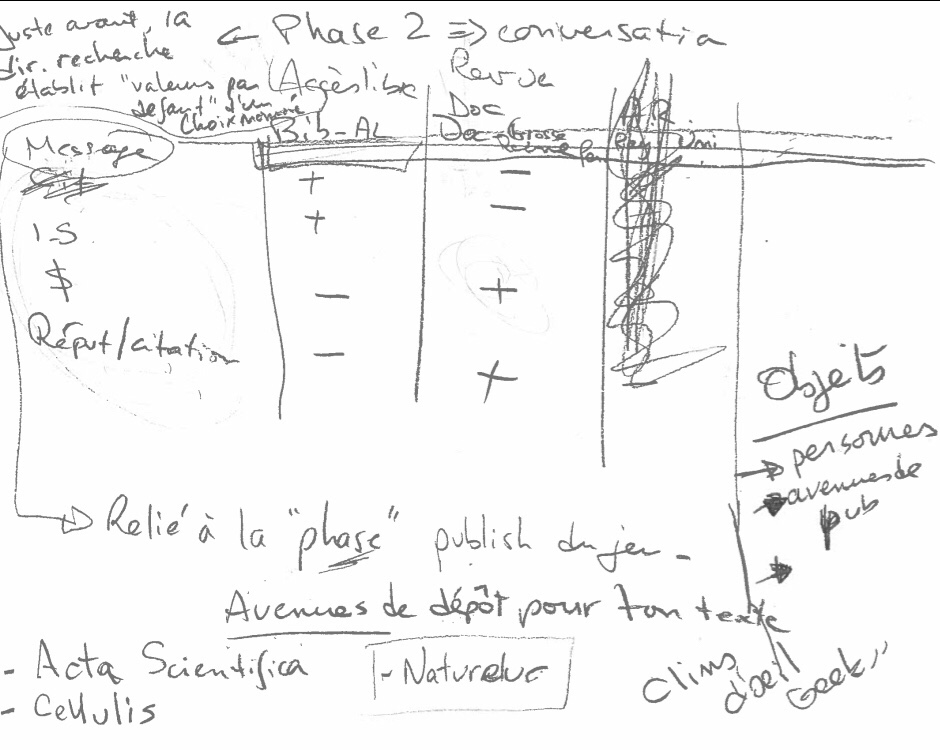
3. Messages des personnages et impacts sur les éléments métriques du jeu, liés à la phase « publication » (troisième) du jeu:
Cette troisième image présente les messages potentiels des personnages du jeu et leur impact (positif, négatif ou neutre) sur les éléments du jeu. Je liste les « objets » du jeu, il y aura probablement uniquement les « avenues de diffusion » pour simplifier les interactions…
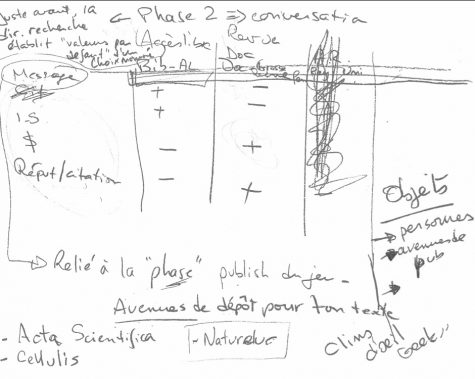
Il faut maintenant mieux travailler ce tableau…
Commerce et Compagnies Document numérique
Algorithmes et droit : liens et lectures
Olivier Charbonneau 2017-11-01
Le 16 octobre dernier avait lieu le colloque Transparence et responsabilité des algorithmes dans le cadre des entretiens Jacques-Cartier au Coeur des sciences de l’UQAM. Outre les exposés, qui furent très enrichissants, et les rencontres, qui furent toutes aussi pertinentes, je vous propose ici une sélection de liens, rapports, livres et autres lectures qui ont fait partie des travaux de la journée:
Livres
Articles
- Joshua A. Kroll , Joanna Huey , Solon Barocas , Edward W. Felten , Joel R. Reidenberg , David G. Robinson & Harlan Yu, Accountable Algorithms, 165 U. Pa. L. Rev. 633 (2017).
Available at: http://scholarship.law.upenn.edu/penn_law_review/vol165/iss3/3
- Brent Daniel Mittelstadt, Patrick Allo, Mariarosaria Taddeo, , Sandra Wachter, Luciano Floridi,The ethics of algorithms: Mapping the debate, Big Data & Society https://doi.org/10.1177/2053951716679679
- Rouvroy Antoinette, Berns Thomas, « Gouvernementalité algorithmique et perspectives d’émancipation. Le disparate comme condition d’individuation par la relation ? », Réseaux, 2013/1 (n° 177), p. 163-196. DOI : 10.3917/res.177.0163. URL : https://www.cairn.info/revue-reseaux-2013-1-page-163.htm
- Jiaming Zeng, Berk Ustun, Cynthia Rudin, Interpretable Classification Models for Recidivism Prediction, arXiv
Autres